
アームの組み立てからテレオペレーションまで、順調に進んできましたLeRobotプロジェクト。今回は、アームに動きを教える学習フェーズに突入します!
今回は ACT (Action Chunking with Transformers) という手法を使って、ロボットアームに動きを学習させていきます。
エピソードの記録
ロボットに動きを覚えてもらうには、まずお手本となる動作データが必要です。
そのため、leaderアームを使用したテレオペレーションでアームを動かしながら、カメラ映像+関節角度やエンドエフェクタ位置などをセットで記録します。
1. 記録環境の準備
今回のタスクは「ペンを掴んでコップの中に入れる」です。この複雑な動きを学習させるために、より多くの情報が必要となります。今回は、2つのカメラを使用して、異なる視点からデータを記録します。
- カメラ1:アームの先端が見えるように取り付け、手元の動きを捉えます
- カメラ2:上から全体を捉え、ペンとコップの位置関係を把握します

使用できるカメラやidなどは`lerobot-find-cameras opencv`コマンドで確認できます。
また、事前に、huggingfaceのトークンも登録しておきました。
2. 記録開始
カメラが接続などの前準備ができたら、ターミナルで以下のコマンドを実行してエピソードの記録を開始します。
lerobot-record \
--robot.type=so101_follower \
--robot.port=/dev/ttyACM数字 \
--robot.id=followerの任意の名前 \
--robot.cameras="{
top: {type: opencv, index_or_path: /dev/video0, width: 640, height: 480, fps: 30},
arm: {type: opencv, index_or_path: /dev/video3, width: 640, height: 480, fps: 30}
}" \
--teleop.type=so101_leader \
--teleop.port=/dev/ttyACM数字 \
--teleop.id=leaderの任意の名前 \
--display_data=true \
--dataset.repo_id=${HF_USER}/データを記録するリポジトリ名 \
--dataset.num_episodes=記録したいエピソード数 \
--dataset.single_task="実行するタスクの概要"このコマンドを実行すると、テレオペレーションが開始され、同時に各ジョイントの動きとカメラ映像の記録が開始されます。
1回分のエピソードは、以下のように行います。
あとは、記録全体を通して一貫した把持動作を維持するように繰り返します。
今回は、100回分のエピソードを記録しました。
シンプルながらも地道な作業で、かなり疲れました…(笑)
ACTによる学習
いよいよ、集めたデータを使ってACTモデルを学習させます。
学習には、次のコマンドを使用しました。
python -m lerobot.scripts.train \
--dataset.repo_id=${HF_USER}/PenPickPlace_100epi \
--policy.type=act \
--output_dir=outputs/train/act_pen_pick_place \
--job_name=act_pen_pick_place \
--policy.device=cuda \
--wandb.enable=true \
--batch_size=16 \
--steps=150000 \
--policy.repo_id=${HF_USER}/act_pen_pick_placewandbを使用して、train lossなどを確認できます。
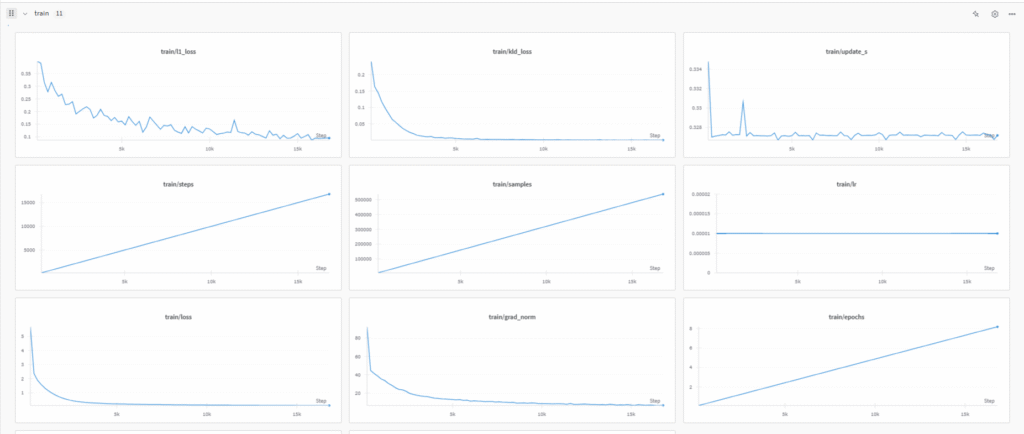
これにより、学習がうまく行っているかチェックできます。
GPUの性能によって学習時間は変わるので、気長に待ちます…
学習済みモデルの評価
学習が終わったら、モデルの腕試しです。実際に推論を実行して、学習したポリシーがどれだけ正確に動作するかを評価します。
以下のコマンドを実行して、いざ推論!
python -m lerobot.record \
--robot.type=so101_follower \
--robot.port=/dev/ttyACM数値 \
--robot.id=followerの任意の名前 \
--robot.cameras="{
top: {type: opencv, index_or_path: /dev/video0, width: 640, height: 480, fps: 30},
arm: {type: opencv, index_or_path: /dev/video2, width: 640, height: 480, fps: 30}
}" \
--dataset.single_task="Grab the black pen and place it in the red cup" \
--display_data=false \
--dataset.repo_id=${HF_USER}/eval_act_pen_pick_place_v1 \
--policy.path=${HF_USER}/act_pen_pick_place \
--dataset.episode_time_s=180 \
--dataset.num_episodes=10これで、3分1エピソードで推論を実行できます。
うまくペンをとってコップの中に入れてくれるのか…?ドキドキ…
すごい!思わず拍手してしまいました👏
少々過学習気味だったので、今後エピソードのとり方や適切なsteps数の設定を模索していきたいです。
まとめ
今回は、テレオペレーションで集めたエピソードデータを使って、ACTモデルを学習させる手順を行いました。データ収集から学習、評価まで、一連の流れを体験することで、ロボット学習の難しさや楽しさを知ることができました。
次回は、いよいよSO-ARMを2つ使って双腕対応に挑戦します!さらに複雑な動きができるようになるのか、楽しみですね。